腾讯云给轻量服务器锐驰型的用户发了相同时长的轻量对象存储 50G 免费额度,正好来体验一下。
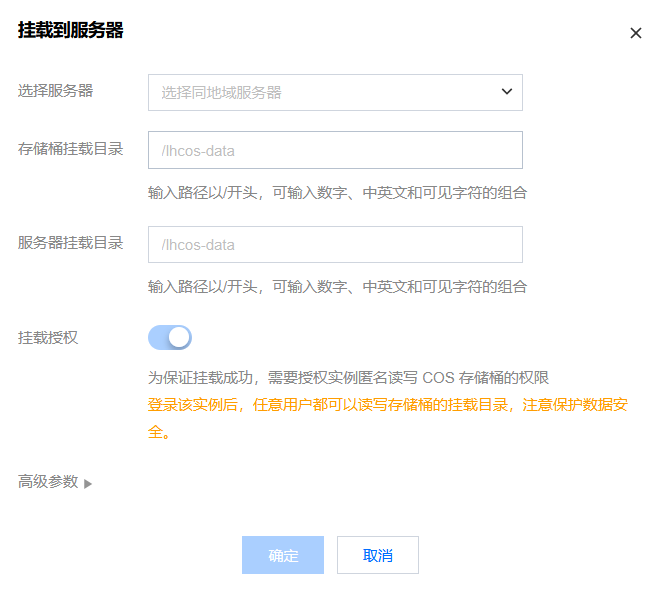
控制台上挂载到轻量服务器上使用
控制台上面非常简洁,看起来基本上就是只希望客户使用这种方式了。使用门槛很低,只需要配置相同地域的服务器(不一定非要锐驰型)和路径就会自动帮忙挂载。
底层也是 cosfs 实现的,应该是用 Agent 自动下发的挂载命令,对新手很友好。搭配 200M 的机器,对于个人开发者来说可以省下一笔不少的费用。
这种方式没有什么更多要说的了,唯一可能要注意的事情是:部分修改文件可能会导致整个文件重传。更多类似限制,可以查阅 cosfs 的相关文档 。另外,cosfs 也有了支持 posix 的后继者 GooseFS-Lite,参见这里 。但未来趋势可能还是存储网关。
当然了,对象存储更多的使用场景还是得通过 API 来进行存取,下面简单来尝试一下。还是有所要注意的地方的。
通过 API/SDK 调用 – 以 Loki 为例
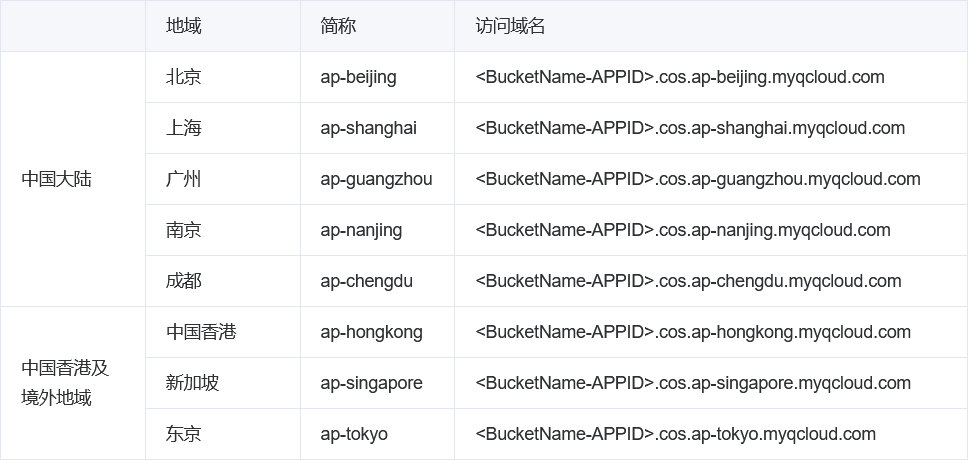
看轻量对象存储的文档 的话,会发现其实它还是支持 API/SDK 调用的,Endpoint 和标准的 COS 是一样的:
那么我们就先来创建子账号和对应所需的权限。经过尝试,如果按照 lhcos(轻量对象存储)进行授权的话,通过 S3 兼容接口调用还是会报错 403,这里按 cos(标准对象存储)授权就可以了。这里也吐槽一下,由于这个 appid 不是用户主账号 uid,就没法使用对象存储的诊断工具了。
{
"statement": [
{
"action": [
"cos:GetBucket",
"cos:GetObject",
"cos:PutObject",
"cos:DeleteObject"
],
"effect": "allow",
"resource": [
"qcs::cos:<region>:uid/<uid>:<bucketName>-<uid>/*"
]
}
],
"version": "2.0"
}配置 Loki 使用轻量对象存储,这里给出关键的配置片段:
loki:
storage:
type: s3
s3:
endpoint: cos.ap-hongkong.myqcloud.com
region: ap-hongkong
accessKeyId: <ak>
secretAccessKey: <sk>
bucketNames:
chunks: <bucketName>-<uid>
ruler: <bucketName>-<uid>
admin: <bucketName>-<uid>
schemaConfig:
configs:
- from: 2024-04-01
object_store: s3
store: tsdb
schema: v13
index:
prefix: index_
period: 24h由于我这里是跨云的集群,如果 CoreDNS 不在内网会导致解析对象存储的 Endpoint 是公网 IP,会把账单打爆,所以这里还需要配置 DNS:(说明一下,这里不知道什么毛病,dnsConfig 居然用了 tpl 方法 ,但是 values.yaml 里面又是个 map ,所以只能喂个 string,然后部署的时候会有警告)
singleBinary:
replicas: 1
nodeSelector:
kubernetes.io/hostname: hkg-qcloud
dnsConfig: |-
nameservers:
- 183.60.83.19
- 183.60.82.98启动后发现 Loki 有报错,日志没有持久化:
level=error ts=2025-04-23T08:34:33.088568269Z caller=flush.go:261 component=ingester loop=29 org_id=xxx msg="failed to flush" retries=1 err="failed to flush chunks: store put chunk: InvalidArgument: invalid x-cos-storage-class for role mode bucket, only support intellingent tiering or default\n\tstatus code: 400, request id: xxx, host id: , num_chunks: 1, labels: {app=\"loki\", component=\"gateway\", container=\"nginx\", filename=\"/var/log/pods/monitoring_loki-gateway-6fb5686c6f-42wcc_ce7d81e7-a5fb-4436-b2e8-51abf866f056/nginx/0.log\", instance=\"loki\", job=\"monitoring/loki\", namespace=\"monitoring\", node_name=\"hkg-qcloud\", pod=\"loki-gateway-6fb5686c6f-42wcc\", service_name=\"loki\", stream=\"stderr\"}"
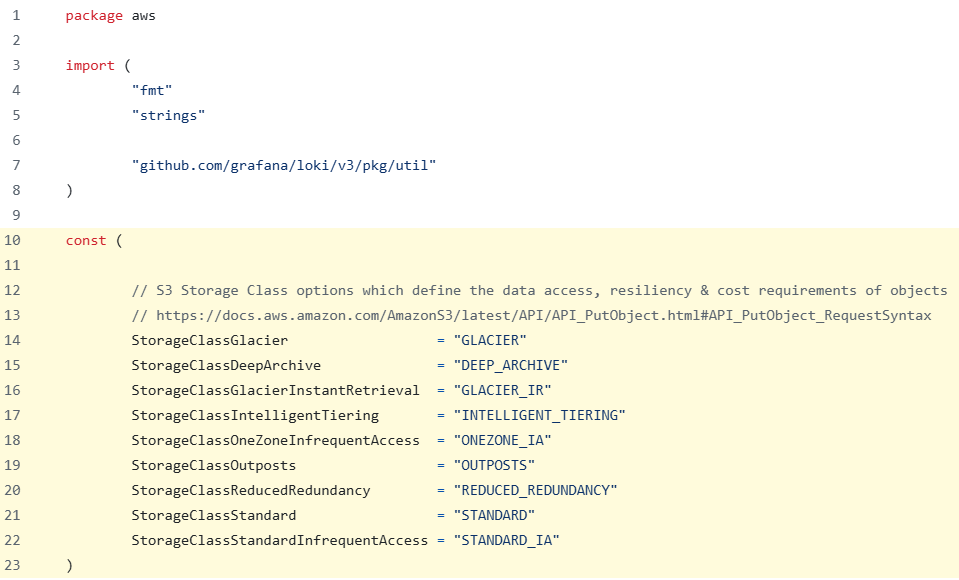
看起来是 Loki 在调用上传的时候,加了对象的预期存储类型,轻量对象存储可能刚好简化了这个类型。尝试从代码 里面找的话, 可以发现确实支持进行配置:
文档中也给出了相应说明:Grafana Loki configuration parameters | Grafana Loki documentation 。所以我们可以新增配置:
loki:
storage_config:
aws:
storage_class: INTELLIGENT_TIERING问题解决。Loki 日志显示开始正常存取日志块,并且轻量对象存储控制台上也能看见相应的文件了。
附录
完整的 Loki values.yaml
deploymentMode: SingleBinary
loki:
commonConfig:
replication_factor: 1
storage:
type: s3
s3:
endpoint: cos.ap-hongkong.myqcloud.com
region: ap-hongkong
accessKeyId: <ak>
secretAccessKey: <sk>
bucketNames:
chunks: <bucketName>-<uid>
ruler: <bucketName>-<uid>
admin: <bucketName>-<uid>
storage_config:
aws:
storage_class: INTELLIGENT_TIERING
schemaConfig:
configs:
- from: 2024-04-01
object_store: s3
store: tsdb
schema: v13
index:
prefix: index_
period: 24h
limits_config:
retention_period: 4320h
compactor:
retention_enabled: true
delete_request_store: s3
singleBinary:
replicas: 1
nodeSelector:
kubernetes.io/hostname: hkg-qcloud
dnsConfig: |-
nameservers:
- 183.60.83.19
- 183.60.82.98
chunksCache:
enabled: false
gateway:
nodeSelector:
kubernetes.io/hostname: hkg-qcloud
resultsCache:
enabled: false
read:
replicas: 0
backend:
replicas: 0
write:
replicas: 0